Agent Harness Engineering
.png)
Agent harness engineering is the discipline of designing everything around an AI model that turns it into a working agent. Here's what the harness includes, why it matters more than the model, and how to build one that can withstand production contact.

May 28, 2026
TL;DR
- Agent harness engineering is the discipline of designing everything around an AI model that turns it into a working agent: prompts, tools, runtime, hooks, credentials, and observability.
- Two principles define the discipline: every observed mistake becomes a permanent constraint, and every component encodes a specific assumption about what the model cannot do on its own.
- Most production agents fail at the boundary components, not the model-facing ones. Credential handling, fallback paths, and third-party tool descriptions cause more outages than prompts or orchestration.
- Agent harness engineering was developed by and for developers. When the agent's user is not a developer, the user cannot maintain the harness, and the platform team has to enforce it instead.
- MCPX, Lunar's MCP gateway, enforces agent harness engineering at the protocol layer: tool curation, vault-backed credentials, per-user attribution, and definition integrity across every MCP server in scope.
What agent harness engineering is
A model is a text generator. By itself, it cannot run code, call an API, or do anything in the world. To turn a model into an agent that takes real actions, you have to surround it with the prompts, tools, runtime, and rules that let it operate. That collection is the harness.
Agent harness engineering is the practice of designing the harness deliberately, the way you would engineer any production system. The term emerged in late 2025 and early 2026 as teams shipping agents noticed that the same model produced very different behavior depending on what was wrapped around it.
This matters because the model is no longer the bottleneck for most production deployments. Across the agent products on the market today (Claude Code, Cursor, Codex, Aider, Cline), the underlying models are often interchangeable. What defines each product is the harness. The clearest evidence: Vivek Trivedy and his team at LangChain moved a coding agent from outside the Top 30 to Top 5 on Terminal Bench 2.0 by changing only the harness, lifting pass rate from 52.8% to 66.5% with the same underlying model. The work is documented in Improving Deep Agents with Harness Engineering. Same model, same task, dramatically different results.
.png)
What goes in an agent harness
A harness has six categories of components. Every production agent has all six, whether they were designed deliberately or not. The difference between a working agent and a brittle one is usually how much of the harness was designed on purpose.
- The system prompt and skill documents. Files like
AGENTS.mdandCLAUDE.mdthat give the model persistent instructions, project conventions, and policies. - Tools. Local functions, MCP servers, command-line tools, and API integrations that the agent can invoke. Each carries a description that the model reads at request time.
- The runtime. Where the agent executes: filesystem access, sandbox boundaries, shell availability, and network egress.
- Orchestration logic. How the agent decomposes work: subagent spawning, model routing, planner/generator/evaluator splits.
- Hooks and middleware. Deterministic code that runs before, during, or after agent actions to enforce rules; the model is not reliable enough to enforce itself.
- Observability. Logs, traces, token accounting, and error attribution. Without it, you cannot iterate on the harness.
The two operating principles
The agent harness engineering discipline has converged on two principles that show up across every serious piece of public writing on the topic.
Every observed mistake becomes a permanent constraint. When an agent makes a mistake, you do not just tell it to do better next time. You change the system so that a specific mistake becomes structurally harder to repeat. A new rule in AGENTS.md. A hook that blocks the destructive command. A tool description rewritten so the model stops misusing it. Good harnesses accumulate constraints through iteration, not brainstorming. Every line should trace to a specific thing that went wrong.
Every harness component encodes a specific assumption about what the model cannot do on its own. A hook exists because the model cannot reliably refuse a destructive action. A tool description exists because the model cannot infer the tool's preconditions. A skill doc exists because the model does not know your codebase conventions. If you cannot say what assumption a component encodes, the component should not be there. When the model improves, and the assumption no longer holds, the component should come out, not stay in the code out of habit. This framing comes from Anthropic's engineering team in Effective Harnesses for Long-Running Agents.
Together, these two principles produce harnesses that grow in capability over time without growing in noise.
How to do agent harness engineering: a practical workflow
Building a harness for the first time is not complicated. Maintaining one well is where the discipline lives. Here is the workflow that shows up across teams doing this well in production.
Start from the task, not the architecture
Define exactly what the agent should do. Be specific. "Reconcile invoices" is not a task definition. "Given a list of open invoices and a list of payments received in the last 30 days, match payments to invoices and produce a report of unmatched items" is a task definition. The harness will only be as good as the precision of the task.
.png)
Build the smallest harness that works
One model, two or three tools, a short system prompt. Run it. Watch it fail.
For every failure, ask which assumption is wrong, and watch for patterns
Each failure is the model violating an assumption you implicitly made about its capabilities. The agent called the wrong tool because the tool description was ambiguous. It hallucinated an API field because the schema was not in context. It ran a destructive command because nothing in the harness flagged it as dangerous. Name the assumption that failed. When the same kind of failure shows up across multiple users or sessions, the right fix is rarely "tell the model to try harder." It is a structural change to the harness.
Encode the constraint at the right layer
A tool description fix lives in the tool description. A behavioral rule lives in the system prompt or in AGENTS.md. A guarantee that has to hold no matter what the model decides lives in a hook. The discipline of choosing the right layer is what separates a harness from a prompt.
Remove components when they stop earning their place
When a model upgrade resolves an assumption you had been encoding, take the workaround out. Components left in place out of habit are how harnesses become bloated and slow.
Where harnesses break in production
Most agent harness writing focuses on the model-facing components: prompts, tools, and orchestration. In practice, the components that decide whether an agent ships are the boundary ones.
Credential resolution
Most agents end up with environment variables holding production API tokens. That credential surface is what the agent will reach for when its governed path fails. Credentials belong in a vault, resolved at runtime, never persisted on user machines. We covered the architecture in Best Practices for MCP Secret Management at Enterprise Scale.
.png)
Fallback paths
Every agent with both governed tools and a shell eventually hits the same pattern. The MCP server fails. The agent has bash. It reasons its way to a curl using the API token sitting in $STRIPE_API_KEY. The harness scoped the happy path. It said nothing about the unhappy one. We covered this failure mode in CLI vs MCP: You're Asking the Wrong Question.
Tool sprawl
Teams start by connecting every MCP server they have access to. A few months later, they have dozens of tools loaded, agent reliability drops, and nobody can tell which tools are being used in which workflows. Ten focused tools beat fifty overlapping ones, because the model can hold a small menu coherently and gets lost in a large one. We covered the runtime side in Why Dynamic Tool Discovery Solves the Context Management Problem.
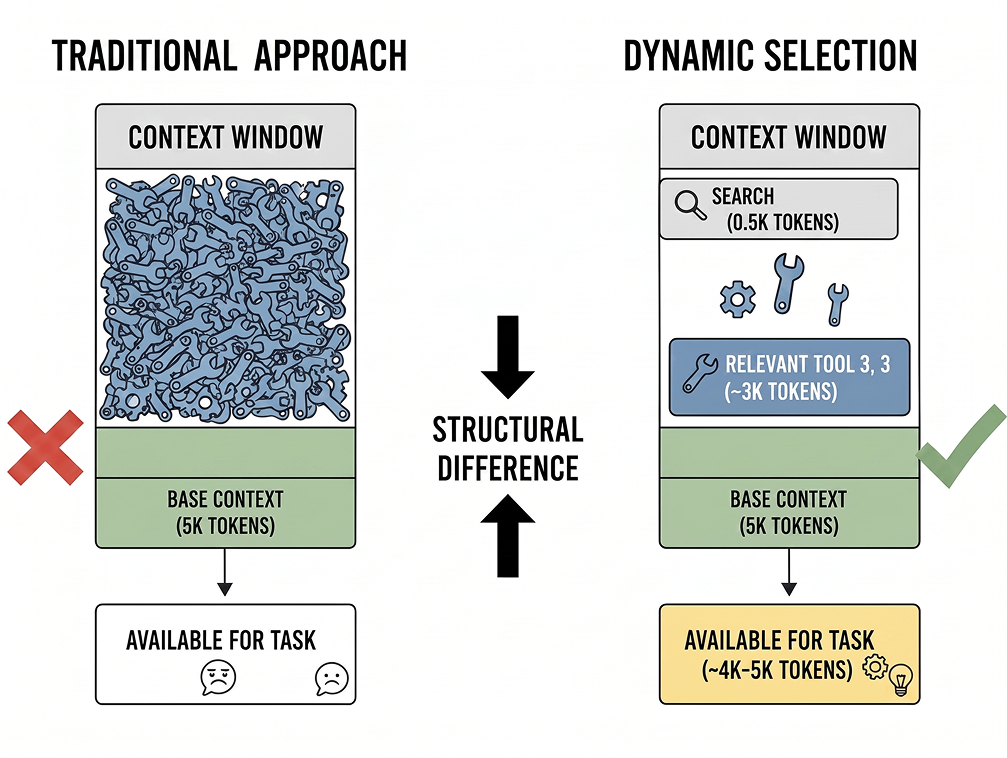
Definition integrity
Third-party MCP servers can mutate their tool descriptions after installation. The harness should pin definitions at discovery time, hash them, and alert on changes. Most do not.
.png)
Per-user attribution
When something goes wrong, the security team's first question is who initiated the action. In most setups, the answer is a shared service account that runs the command on behalf of the team. That is not an audit log.
These five boundary components are not advanced features. They are load-bearing for any agent running with production credentials against systems people care about. A harness that gets the model-facing components right and the boundary components wrong will not survive a security review.
Agent harness engineering for non-developer users
Everything above assumes a specific user: a developer who can read the harness, audit the tool descriptions, and ship the fix when something breaks. That assumption holds across every named source in the agent harness engineering canon. OpenAI's Codex team shipped a million lines of code using these principles with three to seven engineers. Hashimoto, Anthropic, Addy Osmani: same audience. Developers.
That is not the user driving enterprise AI adoption right now.
In the last six months, we have watched teams roll out MCP-enabled agents past engineering into finance, marketing, ops, and customer success. We covered that shift in How to Enable AI for Every Department, Not Just Engineering. For non-developer users, three of the canon's principles fail.
The harness needs to live at the platform layer, defined once for a role and applied to every user in it. MCPX handles this through Profiles and Groups. A Profile is a sub-catalog of your organizational MCP servers and tools, scoped to the needs of a specific role. Marketing can pull from GitHub through read-only tools while engineering keeps write access. Attach a Group from your IdP to a Profile once, and every current and future member inherits the access.
%201%20(1).png)
The ratchet stops working. The first principle requires the user who experiences the mistake to be the user who can encode the constraint. A finance analyst who notices the agent picked the wrong customer name cannot file an AGENTS.md PR. The mistake happens, gets worked around, and happens again to the next user. The ratchet does not ratchet because the feedback path is broken.
Component audit becomes impossible. Anthropic's principle that every component encodes an assumption requires someone to read the components. A developer can open a tool description and notice it undersells preconditions. A finance analyst cannot. The audit work has to happen before the user ever sees the tool surface.
Boundary components have to carry the whole load. When the user can review every command the agent runs, the user is the last line of defense. When the user cannot, the harness has to enforce invariants at the protocol layer, because the user-layer check is not coming.
We call the underlying issue the harness ownership gap: the structural distance between the user who experiences a failure and the team that owns the policy that could prevent it. In a developer harness, the gap is zero. In an enterprise, it is not.
The MCP gateway pattern closes most of this gap. Tool curation moves the audit work from the user to the platform team. Credentials live in the vault, so the agent cannot reach for anything the user could not have granted by hand. Per-user attribution turns failures into visible signals for the team that can fix them, and definition integrity stops third-party MCP servers from mutating tools underneath the user. Each one is an agent harness engineering for a user who cannot maintain the harness themselves.That is not the whole gap. Workflow-level approvals, cost and behavior monitoring across many agents, audit retention, incident response, compliance reporting: that work belongs to a broader agent governance platform, and the gateway is one component of it. MCPX is the floor. The platform above is still being built.
These four mechanisms are not features. They are agent harness engineering for users who cannot maintain the harness themselves.
Where this goes
Enterprise rollouts are a different problem. The harness has to be maintained by someone other than the user. The platform team takes on the audit work, the constraint encoding, and the boundary enforcement. The user gets a stable surface that has been hardened by people who can read it.
That is the part of agent harness engineering still unnamed in public discourse, and it is the part Lunar is built for.
The platform itself is still evolving toward this. Lunar's AI Gateway and MCPX are converging into one governance surface across the full agent stack. The AI Gateway covers the LLM side: prompt sanitation, model routing across providers, rate limits, and token cost controls. MCPX covers the tool side: curation, vault-backed credentials, per-user attribution, and definition integrity. Together, they govern the path from user prompt through LLM to tool execution.
Skills become reusable artifacts that travel with the Profile that owns them, so the constraints one team encoded do not have to be rebuilt by the next. Profiles themselves may evolve into something closer to a shareable agent harness: tool curation, credentials, audit policy, and accumulated constraints in one place, applied across every user in a role.
The terminology will catch up to the work. We are already building it.
The model is the part you did not have to build. The harness is the part you have to build for the user who cannot.
If your team is building agent infrastructure for enterprise users, book a demo or contact our team.
Frequently asked questions
What is agent harness engineering?
The discipline of designing the system around the model: the tools an agent can call, the credentials it uses, and the feedback it gets when something fails. The harness, not the model, usually decides whether an agent is reliable.
How is agent harness engineering different from prompt engineering?
Prompts shape one interaction. The harness shapes every interaction. For enterprise agents, the harness carries most of the reliability load.
Why does agent harness engineering break for non-developer users?
The discipline assumes the user owns the system. Business users cannot change tool wiring, manage credentials, or read agent logs. A platform team has to own the harness for them.
What does an MCP gateway solve for agent harness engineering?
It moves harness work off the user and onto the platform: tool curation, vault-backed credentials, per-user attribution, and protection against tool definition drift. Lunar.dev MCPX is built around this pattern.
Ready to Start your journey?
Govern all agentic traffic in real time with enterprise-grade security and control. Deploy safely on-prem, in your VPC, or hybrid cloud.
.png)
.png)
%20(1).png)
